bRPC源码解析·work_stealing_queue
(作者简介:KIDGINBROOK,在昆仑芯参与训练框架开发工作)
背景
每个bthread_worker都有自己的work_stealing_queue,保存着待执行的bthread,当前的bthread_worker会从queue中pop数据进行处理,如果自己的queue为空,那么会尝试去其他的bthread_worker的queue中steal,所以为了避免锁的开销,brpc设计了lock-free的WorkStealingQueue。
实现细节
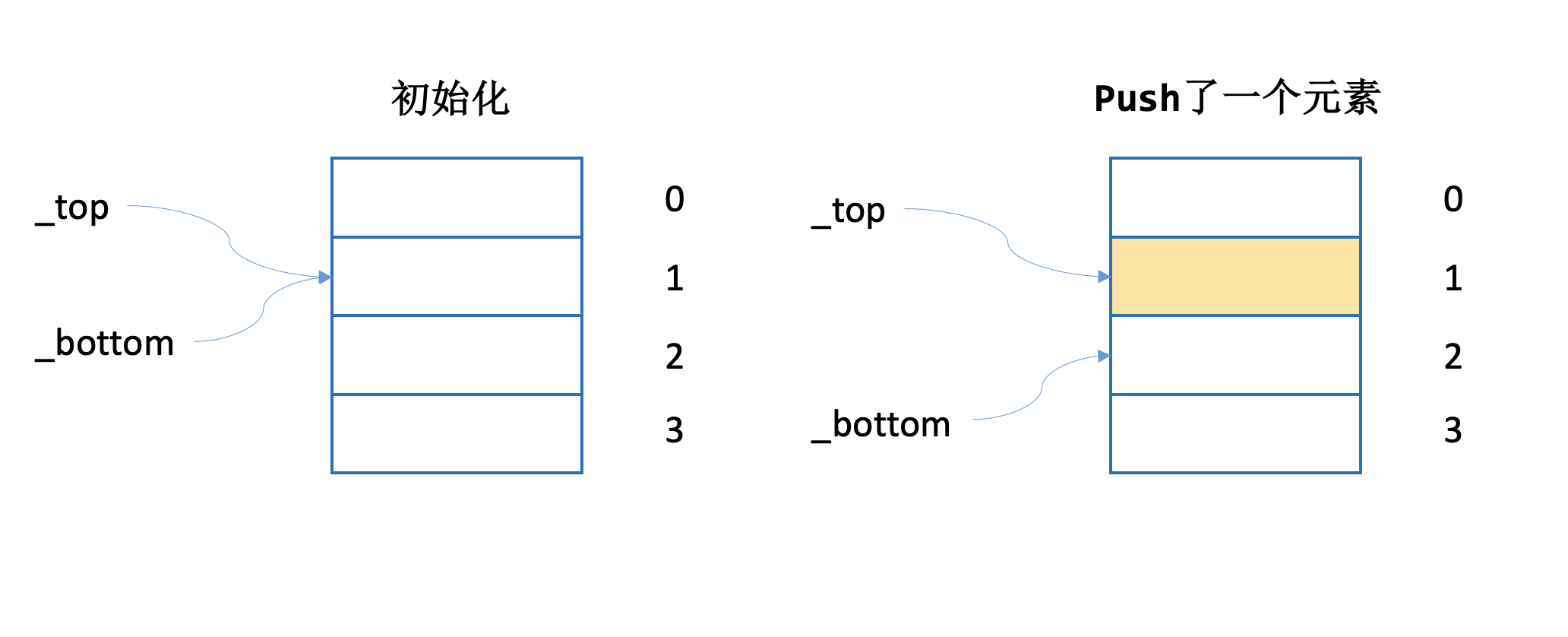 work_stealing_queue如上图所示,push和pop在bottom侧,steal在top侧,不会发生pop和push并发的情况,可能发生并发的情况为,steal和steal,steal和push,steal和pop。
work_stealing_queue如上图所示,push和pop在bottom侧,steal在top侧,不会发生pop和push并发的情况,可能发生并发的情况为,steal和steal,steal和push,steal和pop。
主要接口
push
bool push(const T& x) {
const size_t b = _bottom.load(butil::memory_order_relaxed);
const size_t t = _top.load(butil::memory_order_acquire);
if (b >= t + _capacity) { // Full queue.
return false;
}
_buffer[b & (_capacity - 1)] = x;
_bottom.store(b + 1, butil::memory_order_release); // A
return true;
}
首先看下push,因为steal不会修改bottom,所以bottom用relax读就好,无需同步,而top会被其他bthread_worker修改,因此通过acquire可以看到其他线程release修改top前对内存做的修改;然后判断是否超过queue的容量限制;如果没有超过容量限制,那么在bottom位置写入新数据,并更新bottom;位置A的bottom写入使用release是为了保证steal和pop能看到bottom处的数据写入。
pop
bool pop(T* val) {
const size_t b = _bottom.load(butil::memory_order_relaxed);
size_t t = _top.load(butil::memory_order_relaxed);
if (t >= b) {
// fast check since we call pop() in each sched.
// Stale _top which is smaller should not enter this branch.
return false;
}
const size_t newb = b - 1;
_bottom.store(newb, butil::memory_order_relaxed);
butil::atomic_thread_fence(butil::memory_order_seq_cst); // A
t = _top.load(butil::memory_order_relaxed);
if (t > newb) {
_bottom.store(b, butil::memory_order_relaxed);
return false;
}
*val = _buffer[newb & (_capacity - 1)];
if (t != newb) {
return true;
}
// Single last element, compete with steal()
const bool popped = _top.compare_exchange_strong(
t, t + 1, butil::memory_order_seq_cst, butil::memory_order_relaxed);
_bottom.store(b, butil::memory_order_relaxed);
return popped;
}
通过relax得到的top快速判断是否为空。然后将bottom减一,为了保证同一元素不会既被pop,又被steal,所以加了seq_cst的fence,同steal配对,具体流程后面详述;然后获取top,如果top大于newb,说明queue空,此时需将bottom修改回去;然后将val设置为newb位置的数据;如果t != newb,说明队列中有不止一个数据,此时pop和steal不会竞争,因此直接返回;否则将产生竞争,如果此时top没有发生变化,即还等于t,那么说明此时没有发生steal,将top和bottom统一加一,pop的数据可用;如果top不等于t,那么说明发生了steal,此时需将bottom恢复,pop的数据不可用。
steal
bool steal(T* val) {
size_t t = _top.load(butil::memory_order_acquire);
size_t b = _bottom.load(butil::memory_order_acquire);
if (t >= b) {
// Permit false negative for performance considerations.
return false;
}
do {
butil::atomic_thread_fence(butil::memory_order_seq_cst); // B
b = _bottom.load(butil::memory_order_acquire); // C
if (t >= b) {
return false;
}
*val = _buffer[t & (_capacity - 1)];
} while (!_top.compare_exchange_strong(t, t + 1,
butil::memory_order_seq_cst,
butil::memory_order_relaxed));
return true;
}
然后看下steal,为了能够看到push对buffer的修改,所以这里对bottom的读取使用了acquire,而top用acquire是为了看到pop里对内存的修改。
然后是一个do while循环,steal的B用seq_cst是为了和pop的A配对;C对bottom的acquire读是为了如果B和C之间push进来一个数据,如果不使用acquire可能会导致看到新的bottom,而没有看到新的数据的情况;然后设置val,cas读top,如果没有发生改变,说明此时没有steal和pop在和当前线程发生竞争,那么直接返回;如果top发生改变,说明发生了竞争,那么重新进入循环,这里cas成功时使用seq_cst是为了和steal,pop的cas配对。
最后讲下这几个seq_cst的作用,注意,c++标准中对seq_cst的作用只是在release和acquire语义之上保证了在所有线程间有一个相同的单独全序,而保证不了内存修改的立即全局可见;即memory fence不等于可见性,memory fence保证的是可见性的顺序。
竞争主要为多个steal和pop竞争,此时以三个线程为例,线程1执行pop,线程2和3执行steal,队列中数据为两个,假设top = 0,bottom = 2,可能出问题的情况只能是在全局序中,线程1对bottom的修改在线程2或3的cas之前,否则两个都会被成功steal,pop不成功。
此时情况为,线程1的bottom为1,线程2,3的t = 0,b = 2,因为判断发现队列中有不止一个数据,所以pop返回成功。此时假设线程2成功steal,那么线程3的cas会失败,再下一次循环的时候,将会看到单独全序中之前更新过的bottom值,导致steal失败。如果不使用seq_cst的话将保证不了单独的全序,也就可能看不到之前更新过的bottom,导致既被push,又被pop的错误情况。