bRPC源码解析·IOBuf
(作者简介:KIDGINBROOK,在昆仑芯参与训练框架开发工作)
brpc使用butil::IOBuf作为一些协议中的附件或http body的数据结构,它是一种非连续零拷贝缓冲,在其他项目中得到了验证并有出色的性能。IOBuf的接口和std::string类似,但不相同。
整体架构如下所示,从上到下结构分别为IOBuf,BlockRef和Block,Block负责实际数据的存储,一个IOBuf通过多个BlockRef引用多个Block。
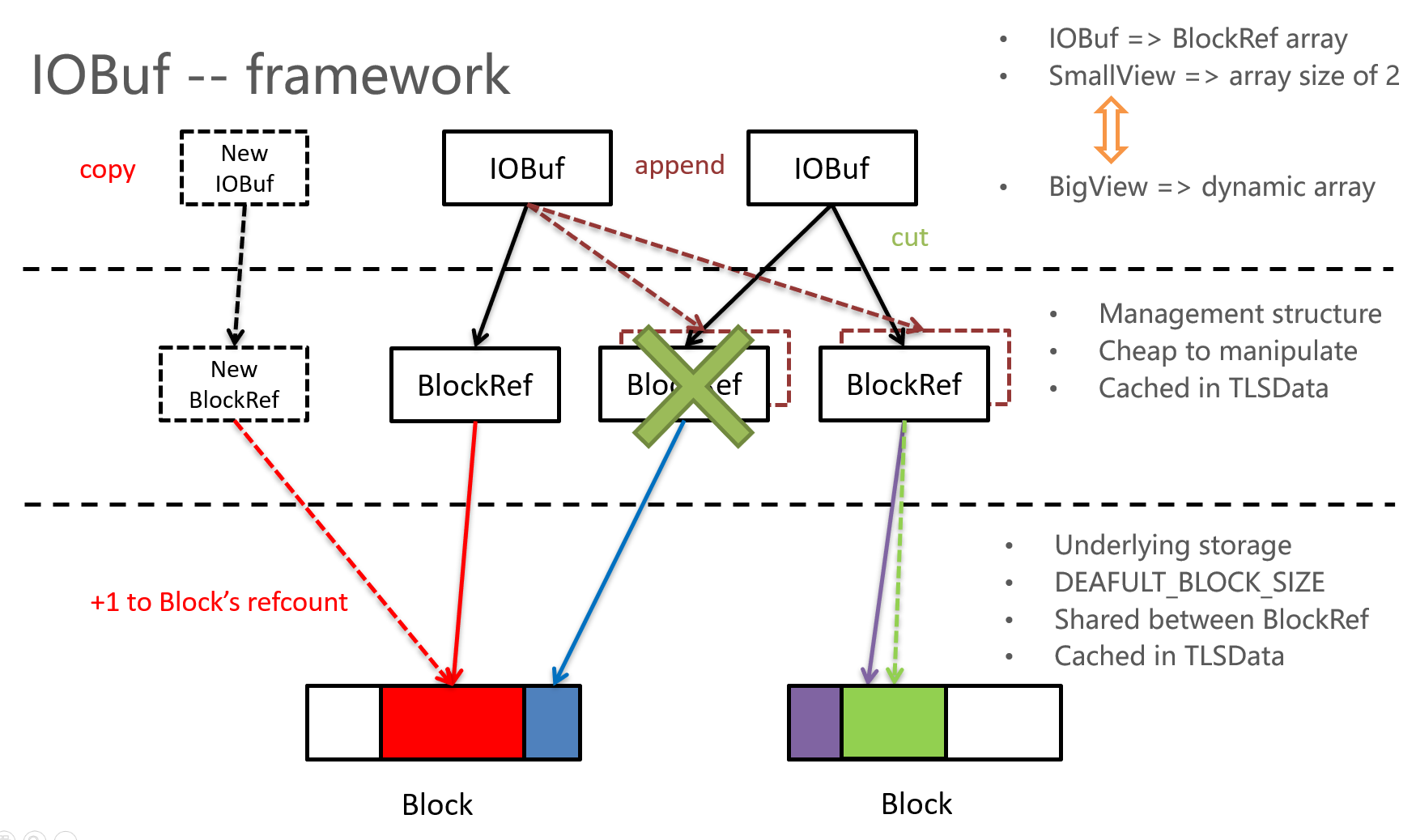
Block
首先看下Block的结构,block就是一段内存,默认大小为8k,负责数据的实际存储。size表示使用了多少内存,cap为这段内存的容量,数据存储在data,portal_next指向在链表结构下的一块block。
struct IOBuf::Block {
butil::atomic<int> nshared;
uint16_t flags;
uint16_t abi_check; // original cap, never be zero.
uint32_t size;
uint32_t cap;
// When flag is 0, portal_next is valid.
// When flag & IOBUF_BLOCK_FLAGS_USER_DATA is non-0, data_meta is valid.
union {
Block* portal_next;
uint64_t data_meta;
} u;
// When flag is 0, data points to `size` bytes starting at `(char*)this+sizeof(Block)'
// When flag & IOBUF_BLOCK_FLAGS_USER_DATA is non-0, data points to the user data and
// the deleter is put in UserDataExtension at `(char*)this+sizeof(Block)'
char* data;
...
}
创建一个block的接口为create_block,block通过blockmem_allocate申请内存,默认设置为malloc,用户可以通过设置blockmem_allocate实现自定义的内存分配,如rdma场景即可通过改写blockmem_allocate实现锁页内存的分配。通过malloc申请到8k内存mem后,在mem上调用placement new,因为block本身也占用了内存,因此实际数据存储data指向mem + sizeof(Block),容量大小为8k-sizeof(Block)。block的写入永远是追加写,不会修改已写入的内容;为了避免全局竞争带来的开销,block引入了tls优化。
static const size_t butil::IOBuf::DEFAULT_BLOCK_SIZE = 8192UL;
void* (*blockmem_allocate)(size_t) = ::malloc;
inline IOBuf::Block* create_block() {
return create_block(IOBuf::DEFAULT_BLOCK_SIZE);
}
inline IOBuf::Block* create_block(const size_t block_size) {
if (block_size > 0xFFFFFFFFULL) {
LOG(FATAL) << "block_size=" << block_size << " is too large";
return NULL;
}
char* mem = (char*)iobuf::blockmem_allocate(block_size);
if (mem == NULL) {
return NULL;
}
return new (mem) IOBuf::Block(mem + sizeof(IOBuf::Block),
block_size - sizeof(IOBuf::Block));
}
block中的nshared字段表示当前block被多少个BlockRef所引用,初始值为1,当block没有被引用时便会被释放。
void inc_ref() {
check_abi();
nshared.fetch_add(1, butil::memory_order_relaxed);
}
void dec_ref() {
check_abi();
if (nshared.fetch_sub(1, butil::memory_order_release) == 1) {
butil::atomic_thread_fence(butil::memory_order_acquire);
if (!flags) {
iobuf::g_nblock.fetch_sub(1, butil::memory_order_relaxed);
iobuf::g_blockmem.fetch_sub(cap + sizeof(Block),
butil::memory_order_relaxed);
this->~Block();
iobuf::blockmem_deallocate(this);
} else if (flags & IOBUF_BLOCK_FLAGS_USER_DATA) {
get_user_data_extension()->deleter(data);
this->~Block();
free(this);
}
}
}
BlockRef
BlockRef引用了一个block,指向了一个block中的一段区域,开始位置为offset,长度为length。
struct BlockRef {
// NOTICE: first bit of `offset' is shared with BigView::start
uint32_t offset;
uint32_t length;
Block* block;
};
IOBuf
然后看下IOBuf,IOBuf本质就是管理了多个BlockRef,IOBuf的主要结构为一个BigView和SmallView的联合体
union {
BigView _bv;
SmallView _sv;
};
sv表示两个Ref,而bv表示一个ref数组
struct SmallView {
BlockRef refs[2];
};
struct BigView {
int32_t magic;
uint32_t start;
BlockRef* refs;
uint32_t nref;
uint32_t cap_mask;
size_t nbytes;
...
}
主要api
然后介绍下IOBuf的主要api。
默认构造函数
首先是默认构造函数,默认为sv
inline void reset_block_ref(IOBuf::BlockRef& ref) {
ref.offset = 0;
ref.length = 0;
ref.block = NULL;
}
inline IOBuf::IOBuf() {
reset_block_ref(_sv.refs[0]);
reset_block_ref(_sv.refs[1]);
}
append一个IOBuf
append一个IOBuf,不涉及到实际内存的拷贝,只要push下other的ref即可,主要逻辑就是ref的合并;遍历other所有的ref,然后调用_push_back_ref
void IOBuf::append(const IOBuf& other) {
const size_t nref = other._ref_num();
for (size_t i = 0; i < nref; ++i) {
_push_back_ref(other._ref_at(i));
}
}
inline void IOBuf::_push_back_ref(const BlockRef& r) {
if (_small()) {
return _push_or_move_back_ref_to_smallview<false>(r);
} else {
return _push_or_move_back_ref_to_bigview<false>(r);
}
}
如果当前IOBuf为sv,那么调用_push_or_move_back_ref_to_smallview,流程如下:
- 如果当前IOBuf没有ref,那么将sv[0]设置为r,并将r所引用的block进行inc_ref()
- 如果当前IOBuf的ref[1]为空,那么判断ref[0]和r是否可以合并,如果两个ref引用的block一致,且两段区域连续,那么就将r合并到ref[0]上,否则将sv[1]设置为r
- 如果当前IOBuf的ref均不为空,那么尝试合并r到ref[1],若无法合并,则将当前iobuf由sv转成bv,为bv申请一定量的ref数组,并将r添加到bv中
如果当前IOBuf为bv,_push_or_move_back_ref_to_bigview则判断r是否能与bv的最后一个合并,若不能,则添加到bv最后。
append一个std::string
此时会涉及内存的拷贝
inline int IOBuf::append(const std::string& s) {
return append(s.data(), s.length());
}
int IOBuf::append(void const* data, size_t count) {
if (BAIDU_UNLIKELY(!data)) {
return -1;
}
if (count == 1) {
return push_back(*((char const*)data));
}
...
}
如果只append一个字符,就会调用push_back()接口,share_tls_block接口是获取到一个未满的block,这个接口后面会介绍,然后将这个字符加到block中,创建ref并push到当前iobuf中,即完成了append。
int IOBuf::push_back(char c) {
IOBuf::Block* b = iobuf::share_tls_block();
if (BAIDU_UNLIKELY(!b)) {
return -1;
}
b->data[b->size] = c;
const IOBuf::BlockRef r = { b->size, 1, b };
++b->size;
_push_back_ref(r);
return 0;
}
如果是append多个字符,那么循环调用share_tls_block得到未满的block,memcpy data到block中,直到拷贝完所有字符。
appendv
int IOBuf::appendv(const const_iovec* vec, size_t n)
该接口是将n个iovec的数据append到iobuf,和上述原理差不多,就是循环执行。 其他对于cut类,pop类接口,原理和append也比较相近,不再赘述。
TLS优化
然后看下之前提到的tls优化。 TLSData就是一个block链表,每个线程有个thread local的TLSData,num_blocks表示cache了多少个block,registered表示是否注册了线程退出对tls清理的函数。
struct TLSData {
// Head of the TLS block chain.
IOBuf::Block* block_head;
// Number of TLS blocks
int num_blocks;
// True if the remote_tls_block_chain is registered to the thread.
bool registered;
};
然后看下上文提到的share_tls_block 首先是判断当前线程TLSData头结点,如果头结点b不是null且未满,那么直接返回b;如果b已经满了,那么将b从tls中移除,dec_ref,并走到b的下一个节点new_block;如果b是null,那么如果没注册线程退出函数就注册下,如果new_block为null,那么通过create_block申请一个block并加入到tls链表中。
IOBuf::Block* share_tls_block() {
TLSData& tls_data = g_tls_data;
IOBuf::Block* const b = tls_data.block_head;
if (b != NULL && !b->full()) {
return b;
}
IOBuf::Block* new_block = NULL;
if (b) {
new_block = b;
while (new_block && new_block->full()) {
IOBuf::Block* const saved_next = new_block->u.portal_next;
new_block->dec_ref();
--tls_data.num_blocks;
new_block = saved_next;
}
} else if (!tls_data.registered) {
tls_data.registered = true;
// Only register atexit at the first time
butil::thread_atexit(remove_tls_block_chain);
}
if (!new_block) {
new_block = create_block(); // may be NULL
if (new_block) {
++tls_data.num_blocks;
}
}
tls_data.block_head = new_block;
return new_block;
}
而acquire_tls_block接口和share_tls_block类似,区别是acquire会将返回的block移除tls,而share不会移除。
release_tls_block,release_tls_block_chain则是将单个/多个block归还TLSData
这里申请和归还block并不能保证在同一个thread,可能会出现在A线程申请,在B线程归还的场景。
IOPortal
然后看下IOPortal,IOPortal是IOBuf的子类,可以从fd中读数据,一般用于和socket的交互。 do while循环做的事情是不断申请block,直到这些block剩余空间能够存下max_count的数据;并初始化好iovec,iovec初始化为这些block;然后调用readv或者preadv,最后根据block生成blockref。
ssize_t IOPortal::pappend_from_file_descriptor(
int fd, off_t offset, size_t max_count) {
iovec vec[MAX_APPEND_IOVEC];
int nvec = 0;
size_t space = 0;
Block* prev_p = NULL;
Block* p = _block;
// Prepare at most MAX_APPEND_IOVEC blocks or space of blocks >= max_count
do {
if (p == NULL) {
p = iobuf::acquire_tls_block();
if (BAIDU_UNLIKELY(!p)) {
errno = ENOMEM;
return -1;
}
if (prev_p != NULL) {
prev_p->u.portal_next = p;
} else {
_block = p;
}
}
vec[nvec].iov_base = p->data + p->size;
vec[nvec].iov_len = std::min(p->left_space(), max_count - space);
space += vec[nvec].iov_len;
++nvec;
if (space >= max_count || nvec >= MAX_APPEND_IOVEC) {
break;
}
prev_p = p;
p = p->u.portal_next;
} while (1);
...
append_from_reader和pappend_from_file_descriptor逻辑差不多,区别是前者使用IReader的ReadV,后者使用系统调用readv或者preadv。
ssize_t IOPortal::pappend_from_file_descriptor(
int fd, off_t offset, size_t max_count) {
...
ssize_t nr = 0;
if (offset < 0) {
nr = readv(fd, vec, nvec);
} else {
static iobuf::iov_function preadv_func = iobuf::get_preadv_func();
nr = preadv_func(fd, vec, nvec, offset);
}
if (nr <= 0) { // -1 or 0
if (empty()) {
return_cached_blocks();
}
return nr;
}
...
}
最后构造BlockRef
ssize_t IOPortal::pappend_from_file_descriptor(
int fd, off_t offset, size_t max_count) {
...
size_t total_len = nr;
do {
const size_t len = std::min(total_len, _block->left_space());
total_len -= len;
const IOBuf::BlockRef r = { _block->size, (uint32_t)len, _block };
_push_back_ref(r);
_block->size += len;
if (_block->full()) {
Block* const saved_next = _block->u.portal_next;
_block->dec_ref(); // _block may be deleted
_block = saved_next;
}
} while (total_len);
return nr;
}
protobuf接口
最后是基于protobuf的IOBufAsZeroCopyInputStream和IOBufAsZeroCopyOutputStream,继承自google::protobuf::io::ZeroCopyInputStream 和google::protobuf::io::ZeroCopyOutputStream,目的是为了消除用户逻辑同stream交互时发生的拷贝,例如从stream的内存到用户的buf间的拷贝;具体做法为buf的内存不应该由用户逻辑管理,而是由stream来管理;对外暴露两个接口,分别为
bool Next(void** data, int* size) // 返回一段可写入的连续内存(*data),长度为(*size)
void BackUp(int count) // 归还不需要使用的内存。
然后看下next接口
bool IOBufAsZeroCopyOutputStream::Next(void** data, int* size) {
if (_cur_block == NULL || _cur_block->full()) {
_release_block();
if (_block_size > 0) {
_cur_block = iobuf::create_block(_block_size);
} else {
_cur_block = iobuf::acquire_tls_block();
}
if (_cur_block == NULL) {
return false;
}
}
const IOBuf::BlockRef r = { _cur_block->size,
(uint32_t)_cur_block->left_space(),
_cur_block };
*data = _cur_block->data + r.offset;
*size = r.length;
_cur_block->size = _cur_block->cap;
_buf->_push_back_ref(r);
_byte_count += r.length;
return true;
}
其实就是申请一个block,然后返回,size为这个block的剩余空间,也因为这样,所以需要acquire来占住整个block。