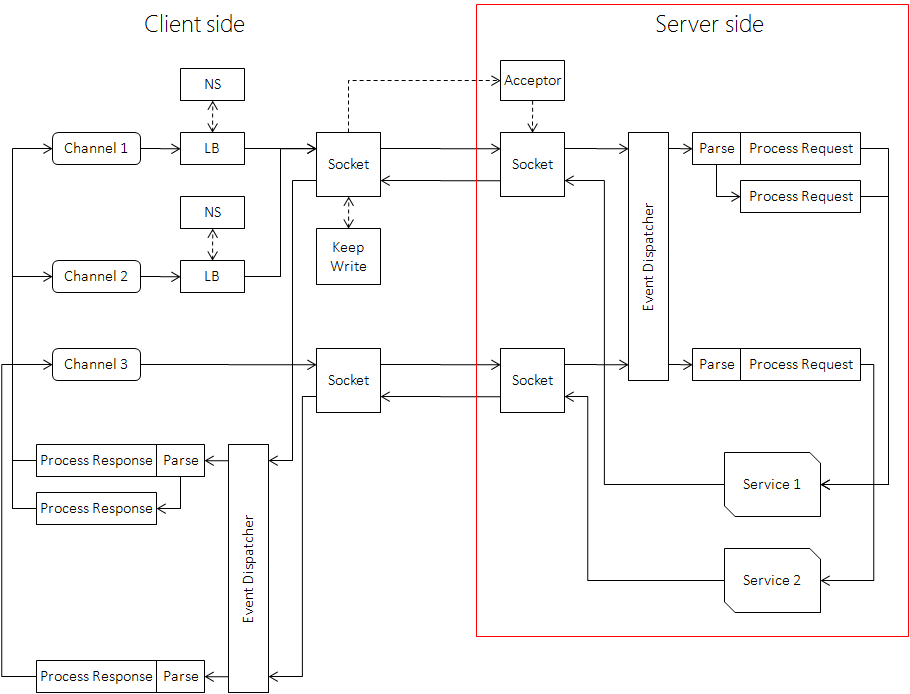
Basics
Example
server-side code of Echo.
Fill the .proto
Interfaces of requests, responses, services are defined in proto files.
# Tell protoc to generate base classes for C++ Service. modify to java_generic_services or py_generic_services for java or python.
option cc_generic_services = true;
message EchoRequest {
required string message = 1;
};
message EchoResponse {
required string message = 1;
};
service EchoService {
rpc Echo(EchoRequest) returns (EchoResponse);
};
Read official documents on protobuf for more details about protobuf.
Implement generated interface
protoc generates echo.pb.cc and echo.pb.h. Include echo.pb.h and implement EchoService inside:
#include "echo.pb.h"
...
class MyEchoService : public EchoService {
public:
void Echo(::google::protobuf::RpcController* cntl_base,
const ::example::EchoRequest* request,
::example::EchoResponse* response,
::google::protobuf::Closure* done) {
// This RAII object calls done->Run() automatically at exit.
brpc::ClosureGuard done_guard(done);
brpc::Controller* cntl = static_cast<brpc::Controller*>(cntl_base);
// fill response
response->set_message(request->message());
}
};
Service is not available before insertion into brpc.Server.
When client sends request, Echo() is called.
Explain parameters:
controller
Statically convertible to brpc::Controller (provided that the code runs in brpc.Server). Contains parameters that can’t be included by request and response, check out src/brpc/controller.h for details.
request
read-only message from a client.
response
Filled by user. If any required field is not set, the RPC will fail.
done
Created by brpc and passed to service’s CallMethod(), including all actions after leaving CallMethod(): validating response, serialization, sending back to client etc.
No matter the RPC is successful or not, done->Run() must be called by user once and only once when the RPC is done.
Why does brpc not call done->Run() automatically? Because users are able to store done somewhere and call done->Run() in some event handlers after leaving CallMethod(), which is an asynchronous service.
We strongly recommend using ClosureGuard to make done->Run() always be called. Look at the beginning statement in above code snippet:
brpc::ClosureGuard done_guard(done);
Not matter the callback is exited from middle or end, done_guard will be destructed, in which done->Run() is called. The mechanism is called RAII. Without done_guard, you have to remember to add done->Run() before each return, which is very error-prone.
In asynchronous service, request is not processed completely when CallMethod() returns, thus done->Run() should not be called, instead it should be preserved somewhere and called later. At first glance, we don’t need ClosureGuard here. However in real applications, asynchronous service may fail in the middle and exit CallMethod() as well. Without ClosureGuard, error branches may forget to call done->Run() before return. Thus done_guard is still recommended in asynchronous services. Different from synchronous services, to prevent done->Run() from being called at successful return of CallMethod, you should call done_guard.release() to remove done from the object.
How synchronous and asynchronous services handle done generally:
class MyFooService: public FooService {
public:
// Synchronous
void SyncFoo(::google::protobuf::RpcController* cntl_base,
const ::example::EchoRequest* request,
::example::EchoResponse* response,
::google::protobuf::Closure* done) {
brpc::ClosureGuard done_guard(done);
...
}
// Aynchronous
void AsyncFoo(::google::protobuf::RpcController* cntl_base,
const ::example::EchoRequest* request,
::example::EchoResponse* response,
::google::protobuf::Closure* done) {
brpc::ClosureGuard done_guard(done);
...
done_guard.release();
}
};
Interface of ClosureGuard:
// RAII: Call Run() of the closure on destruction.
class ClosureGuard {
public:
ClosureGuard();
// Constructed with a closure which will be Run() inside dtor.
explicit ClosureGuard(google::protobuf::Closure* done);
// Call Run() of internal closure if it's not NULL.
~ClosureGuard();
// Call Run() of internal closure if it's not NULL and set it to `done'.
void reset(google::protobuf::Closure* done);
// Set internal closure to NULL and return the one before set.
google::protobuf::Closure* release();
};
Set RPC to be failed
Call Controller.SetFailed() to set the RPC to be failed. If error occurs during sending response, framework calls the method as well. Users often call the method in services’ CallMethod(), For example if a stage of processing fails, user calls SetFailed() and call done->Run(), then quit CallMethod (If ClosureGuard is used, done->Run() is called automatically). The server-side done is created by framework and contains code sending response back to client. If SetFailed() is called, error information is sent to client instead of normal content. When client receives the response, its controller will be SetFailed() as well and Controller::Failed() will be true. In addition, Controller::ErrorCode() and Controller::ErrorText() are error code and error information respectively.
User may set status-code for http calls by calling controller.http_response().set_status_code() at server-side. Standard status-code are defined in http_status_code.h. Controller.SetFailed() sets status-code as well with the value closest to the error-code in semantics. brpc::HTTP_STATUS_INTERNAL_SERVER_ERROR(500) is chosen when there’s no proper value.
Get address of client
controller->remote_side() gets address of the client which sent the request. The return type is butil::EndPoint. If client is nginx, remote_side() is address of nginx. To get address of the “real” client before nginx, set proxy_header ClientIp $remote_addr; in nginx and call controller->http_request().GetHeader("ClientIp") in RPC to get the address.
Printing method:
LOG(INFO) << "remote_side=" << cntl->remote_side();
printf("remote_side=%s\n", butil::endpoint2str(cntl->remote_side()).c_str());
Get address of server
controller->local_side() gets server-side address of the RPC connection, return type is butil::EndPoint.
Printing method:
LOG(INFO) << "local_side=" << cntl->local_side();
printf("local_side=%s\n", butil::endpoint2str(cntl->local_side()).c_str());
Asynchronous Service
In which done->Run() is called after leaving service’s CallMethod().
Some server proxies requests to back-end servers and waits for responses that may come back after a long time. To make better use of threads, save done in corresponding event handlers which are triggered after CallMethod() and call done->Run() inside. This kind of service is asynchronous.
Last line of asynchronous service is often done_guard.release() to prevent done->Run() from being called at successful exit from CallMethod(). Check out example/session_data_and_thread_local for a example.
Server-side and client-side both use done to represent the continuation code after leaving CallMethod, but they’re totally different:
- server-side done is created by framework, called by user after processing of the request to send back response to client.
- client-side done is created by user, called by framework to run post-processing code written by user after completion of RPC.
In an asynchronous service that may access other services, user probably manipulates both kinds of done, be careful.
Add Service
A just default-constructed Server neither contains service nor serves requests, merely an object.
Add a service with following method:
int AddService(google::protobuf::Service* service, ServiceOwnership ownership);
If ownership is SERVER_OWNS_SERVICE, server deletes the service at destruction. To prevent the deletion, set ownership to SERVER_DOESNT_OWN_SERVICE.
Following code adds MyEchoService:
brpc::Server server;
MyEchoService my_echo_service;
if (server.AddService(&my_echo_service, brpc::SERVER_DOESNT_OWN_SERVICE) != 0) {
LOG(FATAL) << "Fail to add my_echo_service";
return -1;
}
You cannot add or remove services after the server is started.
Start server
Call following methods of Server to start serving.
int Start(const char* ip_and_port_str, const ServerOptions* opt);
int Start(EndPoint ip_and_port, const ServerOptions* opt);
int Start(int port, const ServerOptions* opt);
int Start(const char *ip_str, PortRange port_range, const ServerOptions *opt); // r32009后增加
“localhost:9000”, “cq01-cos-dev00.cq01:8000”, “127.0.0.1:7000” are valid ip_and_port_str.
All parameters take default values if options is NULL. If you need non-default values, code as follows:
brpc::ServerOptions options; // with default values
options.xxx = yyy;
...
server.Start(..., &options);
Listen to multiple ports
One server can only listen to one port (not counting ServerOptions.internal_port). To listen to N ports, start N servers .
Multi-process listening to one port
When the reuse_port flag is turned on at startup, multiple processes can listen to one port (use SO_REUSEPORT internal).
Stop server
server.Stop(closewait_ms); // closewait_ms is useless actually, not deleted due to compatibility
server.Join();
Stop() does not block but Join() does. The reason for dividing them into two methods is: When multiple servers quit, users may Stop() all servers first, then Join() them together. Otherwise servers can only be Stop()+Join() one-by-one and the total waiting time may add up to number-of-servers times at worst.
Regardless of the value of closewait_ms, server waits for all requests being processed before exiting and returns ELOGOFF errors to new requests immediately to prevent them from entering the service. The reason for the wait is that as long as the server is still processing requests, risk of accessing invalid(released) memory exists. If a Join() to a server “stucks”, some thread must be blocked on a request or done->Run() is not called.
When a client sees ELOGOFF, it skips the corresponding server and retry the request on another server. As a result, restarting a cluster with brpc clients/servers gradually should not lose traffic by default.
RunUntilAskedToQuit() simplifies the code to run and stop servers in most cases. Following code runs the server until Ctrl-C is pressed.
// Wait until Ctrl-C is pressed, then Stop() and Join() the server.
server.RunUntilAskedToQuit();
// server is stopped, write the code for releasing resources.
Services can be added or removed after Join() returns and server can be Start() again.
Accessed by http/h2
Services using protobuf can be accessed via http/h2+json generally. The json string stored in body is convertible to/from corresponding protobuf message.
echo server as an example, is accessible from curl.
# -H 'Content-Type: application/json' is optional
$ curl -d '{"message":"hello"}' http://brpc.baidu.com:8765/EchoService/Echo
{"message":"hello"}
Note: Set Content-Type: application/proto to access services with http/h2 + protobuf-serialized-data, which performs better at serialization.
json<=>pb
Json fields correspond to pb fields by matched names and message structures. The json must contain required fields in pb, otherwise conversion will fail and corresponding request will be rejected. The json may include undefined fields in pb, but they will be dropped rather than being stored in pb as unknown fields. Check out json <=> protobuf for conversion rules.
When -pb_enum_as_number is turned on, enums in pb are converted to values instead of names. For example in enum MyEnum { Foo = 1; Bar = 2; };, fields typed MyEnum are converted to “Foo” or “Bar” when the flag is off, 1 or 2 otherwise. This flag affects requests sent by clients and responses returned by servers both. Since “enum as name” has better forward and backward compatibilities, this flag should only be turned on to adapt legacy code that are unable to parse enumerations from names.
Adapt old clients
Early-version brpc allows pb service being accessed via http without filling the pb request, even if there’re required fields. This kind of service often parses http requests and sets http responses by itself, and does not touch the pb request. However this behavior is still very dangerous: a service with an undefined request.
This kind of services may meet issues after upgrading to latest brpc, which already deprecated the behavior for a long time. To help these services to upgrade, brpc allows bypassing the conversion from http body to pb request (so that users can parse http requests differently), the setting is as follows:
brpc::ServiceOptions svc_opt;
svc_opt.ownership = ...;
svc_opt.restful_mappings = ...;
svc_opt.allow_http_body_to_pb = false; // turn off conversion from http/h2 body to pb request
server.AddService(service, svc_opt);
After the setting, service does not convert the body to pb request after receiving http/h2 request, which also makes the pb request undefined. Users have to parse the body by themselves when cntl->request_protocol() == brpc::PROTOCOL_HTTP || cntl->request_protocol() == brpc::PROTOCOL_H2 is true which indicates the request is from http/h2.
As a correspondence, if cntl->response_attachment() is not empty and pb response is set as well, brpc does not report the ambiguous anymore, instead cntl->response_attachment() will be used as body of the http/h2 response. This behavior is unaffected by setting allow_http_body_to_pb or not. If the relaxation results in more users’ errors, we may restrict it in future.
Protocols
Server detects supported protocols automatically, without assignment from users. cntl->protocol() gets the protocol being used. Server is able to accept connections with different protocols from one port, users don’t need to assign different ports for different protocols. Even one connection may transport messages in multiple protocols, although we rarely do this (and not recommend). Supported protocols:
The standard protocol used in Baidu, shown as “baidu_std”, enabled by default.
Streaming RPC, shown as “streaming_rpc”, enabled by default.
http/1.0 and http/1.1, shown as “http”, enabled by default.
http/2 and gRPC, shown as “h2c”(unencrypted) or “h2”(encrypted), enabled by default.
Protocol of RTMP, shown as “rtmp”, enabled by default.
Protocol of hulu-pbrpc, shown as “hulu_pbrpc”, enabled by default.
Protocol of sofa-pbrpc, shown as “sofa_pbrpc”, enabled by default.
Protocol of Baidu ads union, shown as “nova_pbrpc”, disabled by default. Enabling method:
#include <brpc/policy/nova_pbrpc_protocol.h> ... ServerOptions options; ... options.nshead_service = new brpc::policy::NovaServiceAdaptor;Protocol of public_pbrpc, shown as “public_pbrpc”, disabled by default. Enabling method:
#include <brpc/policy/public_pbrpc_protocol.h> ... ServerOptions options; ... options.nshead_service = new brpc::policy::PublicPbrpcServiceAdaptor;Protocol of nshead+mcpack, shown as “nshead_mcpack”, disabled by default. Enabling method:
#include <brpc/policy/nshead_mcpack_protocol.h> ... ServerOptions options; ... options.nshead_service = new brpc::policy::NsheadMcpackAdaptor;As the name implies, messages in this protocol are composed by nshead+mcpack, the mcpack does not include special fields. Different from implementations based on NsheadService by users, this protocol uses mcpack2pb which makes the service capable of handling both mcpack and pb with one piece of code. Due to lack of fields to carry ErrorText, server can only close connections when errors occur.
Read Implement NsheadService for UB related protocols.
If you need more protocols, contact us.
fork without exec
In general, forked subprocess should call exec ASAP, before which only async-signal-safe functions should be called. brpc programs using fork like this should work correctly even in previous versions.
But in some scenarios, users continue the subprocess without exec. Since fork only copies its caller’s thread, which causes other threads to disappear after fork. In the case of brpc, bvar depends on a sampling_thread to sample various information, which disappears after fork and causes many bvars to be zeros.
Latest brpc re-creates the thread after fork(when necessary) to make bvar work correctly, and can be forked again. A known problem is that the cpu profiler does not work after fork. However users still can’t call fork at any time, since brpc and its applications create threads extensively, which are not re-created after fork:
- most fork continues with exec, which wastes re-creations
- bring too many troubles and complexities to the code
brpc’s strategy is to create these threads on demand and fork without exec should happen before all code that may create the threads. Specifically, fork without exec should happen before initializing all Servers/Channels/Applications, earlier is better. fork not obeying this causes the program dysfunctional. BTW, fork without exec better be avoided because many libraries do not support it.
Settings
Version
Server.set_version(…) sets name+version for the server, accessible from the builtin service /version. Although it’s called “version”, the string set is recommended to include the service name rather than just a numeric version.
Close idle connections
If a connection does not read or write within the seconds specified by ServerOptions.idle_timeout_sec, it’s treated as “idle” and will be closed by server soon. Default value is -1 which disables the feature.
If -log_idle_connection_close is turned on, a log will be printed before closing.
| Name | Value | Description | Defined At |
|---|---|---|---|
| log_idle_connection_close | false | Print log when an idle connection is closed | src/brpc/socket.cpp |
pid_file
If this field is non-empty, Server creates a file named so at start-up, with pid as the content. Empty by default.
Print hostname in each line of log
This feature only affects logging macros in butil/logging.h.
If -log_hostname is turned on, each line of log contains the hostname so that users know machines at where each line is generated from aggregated logs.
Crash after printing FATAL log
This feature only affects logging macros in butil/logging.h, glog crashes for FATAL log by default.
If -crash_on_fatal_log is turned on, program crashes after printing LOG(FATAL) or failed assertions by CHECK*(), and generates coredump (with proper environmental settings). Default value is false. This flag can be turned on in tests to make sure the program never hit critical errors.
A common convention: use ERROR for tolerable errors, FATAL for unacceptable and permanent errors.
Minimum log level
This feature is implemented by butil/logging.h and glog separately, as a same-named gflag.
Only logs with levels not less than the level specified by -minloglevel are printed. This flag can be modified at run-time. Correspondence between values and log levels: 0=INFO 1=NOTICE 2=WARNING 3=ERROR 4=FATAL, default value is 0.
Overhead of unprinted logs is just a “if” test and parameters are not evaluated (For example a parameter calls a function, if the log is not printed, the function is not called). Logs printed to LogSink may be filtered by the sink as well.
Return free memory to system
Set gflag -free_memory_to_system_interval to make the program try to return free memory to system every so many seconds, values <= 0 disable the feature. Default value is 0. To turn it on, values >= 10 are recommended. This feature supports tcmalloc, thus MallocExtension::instance()->ReleaseFreeMemory() periodically called in your program can be replaced by setting this flag.
Log error to clients
Framework does not print logs for specific client generally, because a lot of errors caused by clients may slow down server significantly due to frequent printing of logs. If you need to debug or just want the server to log all errors, turn on -log_error_text.
Customize percentiles of latency
Latency percentiles showed are 80 (was 50 before), 90, 99, 99.9, 99.99 by default. The first 3 ones can be changed by gflags -bvar_latency_p1, -bvar_latency_p2, -bvar_latency_p3 respectively。
Following are correct settings:
-bvar_latency_p3=97 # p3 is changed from default 99 to 97
-bvar_latency_p1=60 -bvar_latency_p2=80 -bvar_latency_p3=95
Following are wrong settings:
-bvar_latency_p3=100 # the value must be inside [1,99] inclusive,otherwise gflags fails to parse
-bvar_latency_p1=-1 # ^
Change stacksize
brpc server runs code in bthreads with stacksize=1MB by default, while stacksize of pthreads is 10MB. It’s possible that programs running normally on pthreads may meet stack overflow on bthreads.
Set following gflags to enlarge the stacksize.
--stack_size_normal=10000000 # sets stacksize to roughly 10MB
--tc_stack_normal=1 # sets number of stacks cached by each worker pthread to prevent reusing from global pool each time, default value is 8
NOTE: It does mean that coredump of programs is likely to be caused by “stack overflow” on bthreads. We’re talking about this simply because it’s easy and quick to verify this factor and exclude the possibility.
Limit sizes of messages
To protect servers and clients, when a request received by a server or a response received by a client is too large, the server or client rejects the message and closes the connection. The limit is controlled by -max_body_size, in bytes.
An error log is printed when a message is too large and rejected:
FATAL: 05-10 14:40:05: * 0 src/brpc/input_messenger.cpp:89] A message from 127.0.0.1:35217(protocol=baidu_std) is bigger than 67108864 bytes, the connection will be closed. Set max_body_size to allow bigger messages
protobuf has similar limits and the error log is as follows:
FATAL: 05-10 13:35:02: * 0 google/protobuf/io/coded_stream.cc:156] A protocol message was rejected because it was too big (more than 67108864 bytes). To increase the limit (or to disable these warnings), see CodedInputStream::SetTotalBytesLimit() in google/protobuf/io/coded_stream.h.
brpc removes the restriction from protobuf and controls the limit by -max_body_size solely: as long as the flag is large enough, messages will not be rejected and error logs will not be printed. This feature works for all versions of protobuf.
Compression
set_response_compress_type() sets compression method for the response, no compression by default.
Attachment is not compressed. Check here for compression of HTTP body.
Supported compressions:
- brpc::CompressTypeSnappy : snanpy, compression and decompression are very fast, but compression ratio is low.
- brpc::CompressTypeGzip : gzip, significantly slower than snappy, with a higher compression ratio.
- brpc::CompressTypeZlib : zlib, 10%~20% faster than gzip but still significantly slower than snappy, with slightly better compression ratio than gzip.
Read Client-Compression for more comparisons.
Attachment
baidu_std and hulu_pbrpc supports attachments which are sent along with messages and set by users to bypass serialization of protobuf. From a server’s perspective, data set in Controller.response_attachment() will be received by the client while Controller.request_attachment() contains attachment sent from the client.
Attachment is not compressed by framework.
In http, attachment corresponds to message body, namely the data to post to client is stored in response_attachment().
Turn on SSL
Update openssl to the latest version before turning on SSL, since older versions of openssl may have severe security problems and support less encryption algorithms, which is against with the purpose of using SSL. Setup ServerOptions.ssl_options to turn on SSL. Refer to ssl_options.h for more details.
// Certificate structure
struct CertInfo {
// Certificate in PEM format.
// Note that CN and alt subjects will be extracted from the certificate,
// and will be used as hostnames. Requests to this hostname (provided SNI
// extension supported) will be encrypted using this certifcate.
// Supported both file path and raw string
std::string certificate;
// Private key in PEM format.
// Supported both file path and raw string based on prefix:
std::string private_key;
// Additional hostnames besides those inside the certificate. Wildcards
// are supported but it can only appear once at the beginning (i.e. *.xxx.com).
std::vector<std::string> sni_filters;
};
// SSL options at server side
struct ServerSSLOptions {
// Default certificate which will be loaded into server. Requests
// without hostname or whose hostname doesn't have a corresponding
// certificate will use this certificate. MUST be set to enable SSL.
CertInfo default_cert;
// Additional certificates which will be loaded into server. These
// provide extra bindings between hostnames and certificates so that
// we can choose different certificates according to different hostnames.
// See `CertInfo' for detail.
std::vector<CertInfo> certs;
// When set, requests without hostname or whose hostname can't be found in
// any of the cerficates above will be dropped. Otherwise, `default_cert'
// will be used.
// Default: false
bool strict_sni;
// ... Other options
};
To turn on SSL, users MUST provide a
default_cert. For dynamic certificate selection (i.e. based on request hostname, a.k.a SNI),certsshould be used to store those dynamic certificates. Finally, users can add/remove those certificates when server’s running:int AddCertificate(const CertInfo& cert); int RemoveCertificate(const CertInfo& cert); int ResetCertificates(const std::vector<CertInfo>& certs);Other options include: cipher suites (recommend using
ECDHE-RSA-AES256-GCM-SHA384which is the default suite used by chrome, and one of the safest suites. The drawback is more CPU cost), session reuse and so on.SSL layer works under protocol layer. As a result, all protocols (such as HTTP) can provide SSL access when it’s turned on. Server will decrypt the data first and then pass it into each protocol.
After turning on SSL, non-SSL access is still available for the same port. Server can automatically distinguish SSL from non-SSL requests. SSL-only mode can be implemented using
Controller::is_ssl()in service’s callback andSetFailedif it returns false. In the meanwhile, the builtin-service connections also shows the SSL information for each connection.
Verify identities of clients
The server needs to implement Authenticator to enable verifications:
class Authenticator {
public:
// Implement this method to verify credential information `auth_str' from
// `client_addr'. You can fill credential context (result) into `*out_ctx'
// and later fetch this pointer from `Controller'.
// Returns 0 on success, error code otherwise
virtual int VerifyCredential(const std::string& auth_str,
const base::EndPoint& client_addr,
AuthContext* out_ctx) const = 0;
};
class AuthContext {
public:
const std::string& user() const;
const std::string& group() const;
const std::string& roles() const;
const std::string& starter() const;
bool is_service() const;
};
The authentication is connection-specific. When server receives the first request from a connection, it tries to parse related information inside (such as auth field in baidu_std, Authorization header in HTTP), and call VerifyCredential along with address of the client. If the method returns 0, which indicates success, user can put verified information into AuthContext and access it via controller->auth_context() later, whose lifetime is managed by framework. Otherwise the authentication is failed and the connection will be closed, which makes the client-side fail as well.
Subsequent requests are treated as already verified without authenticating overhead.
Assigning an instance of implemented Authenticator to ServerOptions.auth enables authentication. The instance must be valid during lifetime of the server.
Number of worker pthreads
Controlled by ServerOptions.num_threads , number of cpu cores by default(including HT).
NOTE: ServerOptions.num_threads is just a hint.
Don’t think that Server uses exactly so many workers because all servers and channels in one process share worker pthreads. Total number of threads is the maximum of all ServerOptions.num_threads and bthread_concurrency. For example, a program has 2 servers with num_threads=24 and 36 respectively, and bthread_concurrency is 16. Then the number of worker pthreads is max (24, 36, 16) = 36, which is different from other RPC implementations which do summations generally.
Channel does not have a corresponding option, but user can change number of worker pthreads at client-side by setting gflag -bthread_concurrency.
In addition, brpc does not separate “IO” and “processing” threads. brpc knows how to assemble IO and processing code together to achieve better concurrency and efficiency.
Limit concurrency
“Concurrency” may have 2 meanings: one is number of connections, another is number of requests processed simultaneously. Here we’re talking about the latter one.
In traditional synchronous servers, max concurreny is limited by number of worker pthreads. Setting number of workers also limits concurrency. But brpc processes new requests in bthreads and M bthreads are mapped to N workers (M > N generally), synchronous server may have a concurrency higher than number of workers. On the other hand, although concurrency of asynchronous server is not limited by number of workers in principle, we need to limit it by other factors sometimes.
brpc can limit concurrency at server-level and method-level. When number of requests processed by the server or method simultaneously would exceed the limit, server responds the client with brpc::ELIMIT directly instead of invoking the service. A client seeing ELIMIT should retry another server (by best efforts). This options avoids over-queuing of requests at server-side and limits related resources.
Disabled by default.
Why issue error to the client instead of queuing the request when the concurrency hits limit?
A server reaching max concurrency does not mean that other servers in the same cluster reach the limit as well. Let client be aware of the error ASAP and try another server is a better strategy from a cluster view.
Why not limit QPS?
QPS is a second-level metric, which is not good at limiting sudden request bursts. Max concurrency is closely related to availability of critical resources: number of “workers” or “slots” etc, thus better at preventing over-queuing.
In addition, when a server has stable latencies, limiting concurrency has similar effect as limiting QPS due to little’s law. But the former one is much easier to implement: simple additions and minuses from a counter representing the concurrency. This is also the reason than most flow control is implemented by limiting concurrency rather than QPS. For example the window in TCP is a kind of concurrency.
Calculate max concurrency
max_concurrency = peak_qps * noload_latency (little’s law)
peak_qps is the maximum of Queries-Per-Second. noload_latency is the average latency measured in a server without pushing to its limit(with an acceptable latency). peak_qps and nolaod_latency can be measured in pre-online performance tests and multiplied to calculate the max_concurrency.
Limit server-level concurrency
Set ServerOptions.max_concurrency. Default value is 0 which means not limited. Accesses to builtin services are not limited by this option.
Call Server.ResetMaxConcurrency() to modify max_concurrency of the server after starting.
Limit method-level concurrency
server.MaxConcurrencyOf("…") = … sets max_concurrency of the method. Possible settings:
server.MaxConcurrencyOf("example.EchoService.Echo") = 10;
server.MaxConcurrencyOf("example.EchoService", "Echo") = 10;
server.MaxConcurrencyOf(&service, "Echo") = 10;
The code is generally put after AddService, before Start() of the server. When a setting fails(namely the method does not exist), server will fail to start and notify user to fix settings on MaxConcurrencyOf.
When method-level and server-level max_concurrency are both set, framework checks server-level first, then the method-level one.
NOTE: No service-level max_concurrency.
AutoConcurrencyLimiter
max_concurrency may change over time and measuring and setting max_concurrency for all services before each deployment are probably very troublesome and impractical.
AutoConcurrencyLimiter addresses on this issue by limiting concurrency for methods. To use the algorithm, set max_concurrency of the method to “auto”.
// Set auto concurrency limiter for all methods
brpc::ServerOptions options;
options.method_max_concurrency = "auto";
// Set auto concurrency limiter for specific method
server.MaxConcurrencyOf("example.EchoService.Echo") = "auto";
Read this to know more about the algorithm.
pthread mode
User code(client-side done, server-side CallMethod) runs in bthreads with 1MB stacksize by default. But some of them cannot run in bthreads:
- JNI code checks stack layout and cannot be run in bthreads.
- The user code extensively use pthread-local to pass session-level data across functions. If there’s a synchronous RPC call or function calls that may block bthread, the resumed bthread may land on a different pthread which does not have the pthread-local data that users expect to have. As a contrast, although tcmalloc uses pthread(or LWP)-local as well, the code inside has nothing to do with bthread, which is safe.
brpc offers pthread mode to solve the issues. When -usercode_in_pthread is turned on, user code will be run in pthreads. Functions that would block bthreads block pthreads.
Note: With -usercode_in_pthread on, brpc::thread_local_data() does not guarantee to return valid value.
Performance issues when pthread mode is on:
- Since synchronous RPCs block worker pthreads, server often needs more workers (ServerOptions.num_threads), and scheduling efficiencies will be slightly lower.
- User code still runs in special bthreads actually, which use stacks of pthread workers. These special bthreads are scheduled same with normal bthreads and performance differences are negligible.
- bthread supports an unique feature: yield pthread worker to a newly created bthread to reduce a context switch. brpc client uses this feature to reduce number of context switches in one RPC from 3 to 2. In a performance-demanding system, reducing context-switches improves performance. However pthread-mode is not capable of doing this.
- Number of threads in pthread-mode is a hard limit. Once all threads are occupied, requests will be queued rapidly and many of them will be timed-out finally. An example: When many requests to downstream servers are timedout, the upstream services may also be severely affected by a lot of blocking threads waiting for responses(within timeout). Consider setting ServerOptions.max_concurrency to protect the server when pthread-mode is on. As a contrast, number of bthreads in bthread mode is a soft limit and reacts more smoothly to such kind of issues.
pthread-mode lets legacy code to try brpc more easily, but we still recommend refactoring the code with bthread-local or even remove TLS gradually, to turn off the option in future.
Security mode
If requests are from public(including being proxied by nginx etc), you have to be aware of some security issues.
Hide builtin services from public
Builtin services are useful, on the other hand include a lot of internal information and shouldn’t be exposed to public. There’re multiple methods to hide builtin services from public:
Set internal port. Set ServerOptions.internal_port to a port which can only be accessible from internal. You can view builtin services via internal_port, while accesses from the public port (the one passed to Server.Start) should see following error:
[a27eda84bcdeef529a76f22872b78305] Not allowed to access builtin services, try ServerOptions.internal_port=... instead if you're inside internal networkhttp proxies only proxy specified URLs. nginx etc is able to configure how to map different URLs to back-end servers. For example the configure below maps public traffic to /MyAPI to
/ServiceName/MethodNameoftarget-server. If builtin services like /status are accessed from public, nginx rejects the attempts directly.
location /MyAPI {
...
proxy_pass http://<target-server>/ServiceName/MethodName$query_string # $query_string is a nginx varible, check out http://nginx.org/en/docs/http/ngx_http_core_module.html for more.
...
}
Don’t turn on -enable_dir_service and -enable_threads_service on public services. Although they’re convenient for debugging, they also expose too many information on the server. The script to check if the public service has enabled the options:
curl -s -m 1 <HOSTNAME>:<PORT>/flags/enable_dir_service,enable_threads_service | awk '{if($3=="false"){++falsecnt}else if($3=="Value"){isrpc=1}}END{if(isrpc!=1||falsecnt==2){print "SAFE"}else{print "NOT SAFE"}}'
Disable built-in services completely
Set ServerOptions.has_builtin_services = false, you can completely disable the built-in services.
Escape URLs controllable from public
brpc::WebEscape() escapes url to prevent injection attacks with malice.
Not return addresses of internal servers
Consider returning signatures of the addresses. For example after setting ServerOptions.internal_port, addresses in error information returned by server is replaced by their MD5 signatures.
Customize /health
/health returns “OK” by default. If the content on /health needs to be customized: inherit HealthReporter and implement code to generate the page (like implementing other http services). Assign an instance to ServerOptions.health_reporter, which is not owned by server and must be valid during lifetime of the server. Users may return richer healthy information according to application requirements.
thread-local variables
Searching services inside Baidu use thread-local storage (TLS) extensively. Some of them cache frequently used objects to reduce repeated creations, some of them pass contexts to global functions implicitly. You should avoid the latter usage as much as possible. Such functions cannot even run without TLS, being hard to test. brpc provides 3 mechanisms to solve issues related to thread-local storage.
session-local
A session-local data is bound to a server-side RPC: from entering CallMethod of the service, to calling the server-side done->Run(), no matter the service is synchronous or asynchronous. All session-local data are reused as much as possible and not deleted before stopping the server.
After setting ServerOptions.session_local_data_factory, call Controller.session_local_data() to get a session-local data. If ServerOptions.session_local_data_factory is unset, Controller.session_local_data() always returns NULL.
If ServerOptions.reserved_session_local_data is greater than 0, Server creates so many data before serving.
Example
struct MySessionLocalData {
MySessionLocalData() : x(123) {}
int x;
};
class EchoServiceImpl : public example::EchoService {
public:
...
void Echo(google::protobuf::RpcController* cntl_base,
const example::EchoRequest* request,
example::EchoResponse* response,
google::protobuf::Closure* done) {
...
brpc::Controller* cntl = static_cast<brpc::Controller*>(cntl_base);
// Get the session-local data which is created by ServerOptions.session_local_data_factory
// and reused between different RPC.
MySessionLocalData* sd = static_cast<MySessionLocalData*>(cntl->session_local_data());
if (sd == NULL) {
cntl->SetFailed("Require ServerOptions.session_local_data_factory to be set with a correctly implemented instance");
return;
}
...
struct ServerOptions {
...
// The factory to create/destroy data attached to each RPC session.
// If this field is NULL, Controller::session_local_data() is always NULL.
// NOT owned by Server and must be valid when Server is running.
// Default: NULL
const DataFactory* session_local_data_factory;
// Prepare so many session-local data before server starts, so that calls
// to Controller::session_local_data() get data directly rather than
// calling session_local_data_factory->Create() at first time. Useful when
// Create() is slow, otherwise the RPC session may be blocked by the
// creation of data and not served within timeout.
// Default: 0
size_t reserved_session_local_data;
};
session_local_data_factory is typed DataFactory. You have to implement CreateData and DestroyData inside.
NOTE: CreateData and DestroyData may be called by multiple threads simultaneously. Thread-safety is a must.
class MySessionLocalDataFactory : public brpc::DataFactory {
public:
void* CreateData() const {
return new MySessionLocalData;
}
void DestroyData(void* d) const {
delete static_cast<MySessionLocalData*>(d);
}
};
MySessionLocalDataFactory g_session_local_data_factory;
int main(int argc, char* argv[]) {
...
brpc::Server server;
brpc::ServerOptions options;
...
options.session_local_data_factory = &g_session_local_data_factory;
...
server-thread-local
A server-thread-local is bound to a call to service’s CallMethod, from entering service’s CallMethod, to leaving the method. All server-thread-local data are reused as much as possible and will not be deleted before stopping the server. server-thread-local is implemented as a special bthread-local.
After setting ServerOptions.thread_local_data_factory, call brpc::thread_local_data() to get a thread-local. If ServerOptions.thread_local_data_factory is unset, brpc::thread_local_data() always returns NULL.
If ServerOptions.reserved_thread_local_data is greater than 0, Server creates so many data before serving.
Differences with session-local
session-local data is got from server-side Controller, server-thread-local can be got globally from any function running directly or indirectly inside a thread created by the server.
session-local and server-thread-local are similar in a synchronous service, except that the former one has to be created from a Controller. If the service is asynchronous and the data needs to be accessed from done->Run(), session-local is the only option, because server-thread-local is already invalid after leaving service’s CallMethod.
Example
struct MyThreadLocalData {
MyThreadLocalData() : y(0) {}
int y;
};
class EchoServiceImpl : public example::EchoService {
public:
...
void Echo(google::protobuf::RpcController* cntl_base,
const example::EchoRequest* request,
example::EchoResponse* response,
google::protobuf::Closure* done) {
...
brpc::Controller* cntl = static_cast<brpc::Controller*>(cntl_base);
// Get the thread-local data which is created by ServerOptions.thread_local_data_factory
// and reused between different threads.
// "tls" is short for "thread local storage".
MyThreadLocalData* tls = static_cast<MyThreadLocalData*>(brpc::thread_local_data());
if (tls == NULL) {
cntl->SetFailed("Require ServerOptions.thread_local_data_factory "
"to be set with a correctly implemented instance");
return;
}
...
struct ServerOptions {
...
// The factory to create/destroy data attached to each searching thread
// in server.
// If this field is NULL, brpc::thread_local_data() is always NULL.
// NOT owned by Server and must be valid when Server is running.
// Default: NULL
const DataFactory* thread_local_data_factory;
// Prepare so many thread-local data before server starts, so that calls
// to brpc::thread_local_data() get data directly rather than calling
// thread_local_data_factory->Create() at first time. Useful when Create()
// is slow, otherwise the RPC session may be blocked by the creation
// of data and not served within timeout.
// Default: 0
size_t reserved_thread_local_data;
};
thread_local_data_factory is typed DataFactory. You need to implement CreateData and DestroyData inside.
NOTE: CreateData and DestroyData may be called by multiple threads simultaneously. Thread-safety is a must.
class MyThreadLocalDataFactory : public brpc::DataFactory {
public:
void* CreateData() const {
return new MyThreadLocalData;
}
void DestroyData(void* d) const {
delete static_cast<MyThreadLocalData*>(d);
}
};
MyThreadLocalDataFactory g_thread_local_data_factory;
int main(int argc, char* argv[]) {
...
brpc::Server server;
brpc::ServerOptions options;
...
options.thread_local_data_factory = &g_thread_local_data_factory;
...
bthread-local
Session-local and server-thread-local are enough for most servers. However, in some cases, we need a more general thread-local solution. In which case, you can use bthread_key_create, bthread_key_destroy, bthread_getspecific, bthread_setspecific etc, which are similar to pthread equivalence.
These functions support both bthread and pthread. When they are called in bthread, bthread private variables are returned; When they are called in pthread, pthread private variables are returned. Note that the “pthread private” here is not created by pthread_key_create, pthread-local created by pthread_key_create cannot be got by bthread_getspecific. __thread in GCC and thread_local in c++11 etc cannot be got by bthread_getspecific as well.
Since brpc creates a bthread for each request, the bthread-local in the server behaves specially: a bthread created by server does not delete bthread-local data at exit, instead it returns the data to a pool in the server for later reuse. This prevents bthread-local from constructing and destructing frequently along with creation and destroying of bthreads. This mechanism is transparent to users.
Main interfaces
// Create a key value identifying a slot in a thread-specific data area.
// Each thread maintains a distinct thread-specific data area.
// `destructor', if non-NULL, is called with the value associated to that key
// when the key is destroyed. `destructor' is not called if the value
// associated is NULL when the key is destroyed.
// Returns 0 on success, error code otherwise.
extern int bthread_key_create(bthread_key_t* key, void (*destructor)(void* data));
// Delete a key previously returned by bthread_key_create().
// It is the responsibility of the application to free the data related to
// the deleted key in any running thread. No destructor is invoked by
// this function. Any destructor that may have been associated with key
// will no longer be called upon thread exit.
// Returns 0 on success, error code otherwise.
extern int bthread_key_delete(bthread_key_t key);
// Store `data' in the thread-specific slot identified by `key'.
// bthread_setspecific() is callable from within destructor. If the application
// does so, destructors will be repeatedly called for at most
// PTHREAD_DESTRUCTOR_ITERATIONS times to clear the slots.
// NOTE: If the thread is not created by brpc server and lifetime is
// very short(doing a little thing and exit), avoid using bthread-local. The
// reason is that bthread-local always allocate keytable on first call to
// bthread_setspecific, the overhead is negligible in long-lived threads,
// but noticeable in shortly-lived threads. Threads in brpc server
// are special since they reuse keytables from a bthread_keytable_pool_t
// in the server.
// Returns 0 on success, error code otherwise.
// If the key is invalid or deleted, return EINVAL.
extern int bthread_setspecific(bthread_key_t key, void* data);
// Return current value of the thread-specific slot identified by `key'.
// If bthread_setspecific() had not been called in the thread, return NULL.
// If the key is invalid or deleted, return NULL.
extern void* bthread_getspecific(bthread_key_t key);
How to use
Create a bthread_key_t which represents a kind of bthread-local variable.
Use bthread_[get|set]specific to get and set bthread-local variables. First-time access to a bthread-local variable from a bthread returns NULL.
Delete a bthread_key_t after no thread is using bthread-local associated with the key. If a bthread_key_t is deleted during usage, related bthread-local data are leaked.
static void my_data_destructor(void* data) {
...
}
bthread_key_t tls_key;
if (bthread_key_create(&tls_key, my_data_destructor) != 0) {
LOG(ERROR) << "Fail to create tls_key";
return -1;
}
// in some thread ...
MyThreadLocalData* tls = static_cast<MyThreadLocalData*>(bthread_getspecific(tls_key));
if (tls == NULL) { // First call to bthread_getspecific (and before any bthread_setspecific) returns NULL
tls = new MyThreadLocalData; // Create thread-local data on demand.
CHECK_EQ(0, bthread_setspecific(tls_key, tls)); // set the data so that next time bthread_getspecific in the thread returns the data.
}
Example
static void my_thread_local_data_deleter(void* d) {
delete static_cast<MyThreadLocalData*>(d);
}
class EchoServiceImpl : public example::EchoService {
public:
EchoServiceImpl() {
CHECK_EQ(0, bthread_key_create(&_tls2_key, my_thread_local_data_deleter));
}
~EchoServiceImpl() {
CHECK_EQ(0, bthread_key_delete(_tls2_key));
};
...
private:
bthread_key_t _tls2_key;
}
class EchoServiceImpl : public example::EchoService {
public:
...
void Echo(google::protobuf::RpcController* cntl_base,
const example::EchoRequest* request,
example::EchoResponse* response,
google::protobuf::Closure* done) {
...
// You can create bthread-local data for your own.
// The interfaces are similar with pthread equivalence:
// pthread_key_create -> bthread_key_create
// pthread_key_delete -> bthread_key_delete
// pthread_getspecific -> bthread_getspecific
// pthread_setspecific -> bthread_setspecific
MyThreadLocalData* tls2 = static_cast<MyThreadLocalData*>(bthread_getspecific(_tls2_key));
if (tls2 == NULL) {
tls2 = new MyThreadLocalData;
CHECK_EQ(0, bthread_setspecific(_tls2_key, tls2));
}
...
FAQ
Q: Fail to write into fd=1865 SocketId=8905@10.208.245.43:54742@8230: Got EOF
A: The client-side probably uses pooled or short connections, and closes the connection after RPC timedout, when server writes back response, it finds that the connection has been closed and reports this error. “Got EOF” just means the server has received EOF (remote side closes the connection normally). If the client side uses single connection, server rarely reports this error.
Q: Remote side of fd=9 SocketId=2@10.94.66.55:8000 was closed
It’s not an error, it’s a common warning representing that remote side has closed the connection(EOF). This log might be useful for debugging problems.
Disabled by default. Set gflag -log_connection_close to true to enable it. (modify at run-time is supported)
Q: Why does setting number of threads at server-side not work
All brpc servers in one process share worker pthreads, If multiple servers are created, number of worker pthreads is probably the maxmium of their ServerOptions.num_threads.
Q: Why do client-side latencies much larger than the server-side ones
server-side worker pthreads may not be enough and requests are significantly delayed. Read Server debugging for steps on debugging server-side issues quickly.
Q: Fail to open /proc/self/io
Some kernels do not provide this file. Correctness of the service is unaffected, but following bvars are not updated:
process_io_read_bytes_second
process_io_write_bytes_second
process_io_read_second
process_io_write_second
Q: json string “[1,2,3]” can’t be converted to protobuf message
This is not a valid json string, which must be a json object enclosed with braces {}.
PS:Workflow at server-side